您的位置:首页 → 安卓游戏 → 动作闯关 → 音频转文字识别最新版

音频转文字识别工具专注于语音智能解析,具备高效特性,能够实现实时语音输入、本地音频文件以及在线音视频链接的一键转写功能。借助前沿的语音识别引擎,该工具无需网络支持就能完成高精度的文字转换,同时兼顾多语言识别、离线处理和隐私保护等优势,是学生整理课堂笔记、职场人士速记会议内容、创作者提取采访素材的理想之选。
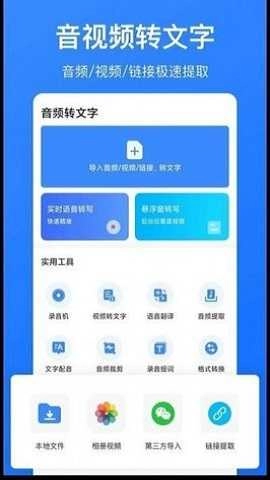
全面兼容MP3、WAV、M4A、AAC等主流音频格式,适配录音、会议设备输出、播客等多种来源;转录过程响应迅速,批量处理流畅不卡顿,大幅提升日常办公与学习效率;提供个性化识别配置功能,用户可依据口音、语境或专业术语库优化识别模型,获取更符合实际需求的文字结果。
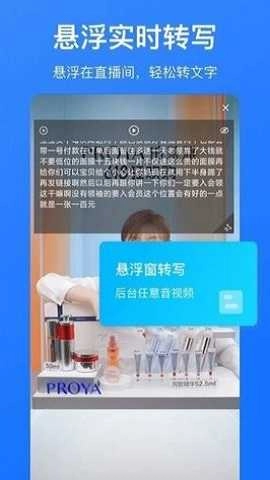
大文件智能分片处理机制,可轻松应对时长数小时的录音,避免因文件体积过大引发中断或失败问题;整合了音频格式转换、智能分段标记、实时转写预览、文字校对编辑等一站式功能,操作流程简洁直观;运用自适应降噪与语境理解技术,能有效识别中英文混合、快语速、轻声细语及常见背景噪音环境下的语音内容,显著提升识别的稳定性与可读性。
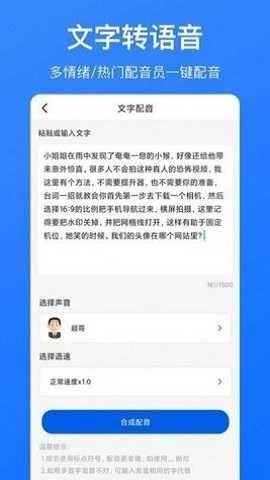
大幅削减人工听写的成本,把原本需要数小时的会议记录、课程复盘等工作缩短到几分钟内完成;同时具备语音翻译和文字转语音功能,能够满足跨语言沟通以及无障碍阅读的需求;所有音频处理默认在设备端进行,原始文件不会上传、不连接网络、不留下痕迹,真正做到数据由用户自主掌控;可以广泛应用于教学备课、法律笔录、医疗问诊、自媒体脚本整理、外语听力训练等多种场景,并且支持离线使用,安全又可靠。
支持WAV、MP3、AAC等多种无损及压缩音频格式的导入;在转写过程中,用户可以随时切换识别语言或调整语速参数,还能即时查看对应段落的文字结果;同时提供算法灵敏度调节和专业词库加载的入口,方便用户依据不同领域特性(例如医学、法律、IT等)进一步提高识别的准确率。
实测识别能力已覆盖中、英、日、韩等十余种常用语言,对于混音环境、多人对话、带口音的普通话以及中英夹杂的表达都具有良好的适应性;系统能够自动识别并区分不同说话人,标记停顿和语气词,生成结构清晰、标点合理的可编辑文本;此外还附加了语音合成模块,支持多种音色、语速与语调的调节,既可以用于听觉复核,也方便制作有声内容或辅助视障用户使用。









 查看
查看
 查看
查看
 查看
查看

角色扮演 115.7MB

角色扮演 156.5MB

角色扮演 167.0MB








